

Version 1 (25k release)
Changelog
- Lossless CRAM replaces the BAM format for reads alignement files
- Sample IDs in CRAM and VCF files are updated to keep only the QPHI unique ID
- New Individual and cohort-level Quality Control (QC) steps introduced in the QGP Pre-Aggregation QC pipeline V1, to remove samples with sequencing issues
- New file formats are delivered for each release (Plink, Hail, PCs, Relatedness, etc.)
- New variants callers (SV, CNV, PGx, SMN, HLA, STRs, etc.)
- New iterative approache for cohort gVCF aggregation, introduced in the QGP Aggregation pipeline v1.0
- New releases file structure for individual and cohort-level files
- New annotation databases (HGMD pro) added to the msVCF, in addition to standard public annotation databases
Genomes
Genomic data release Version 1 provides germline genomes (WGS) of 24,838 healthy participants, from Qatar BioBank (QBB) population-based cohort. This release is generated using the Aggregation pipeline (v1.0).
As part of this release, we’re providing several data formats, in addition to the multi-sample VCF file, to make it easier and faster for researchers to analyze the cohort. Below are the files included:
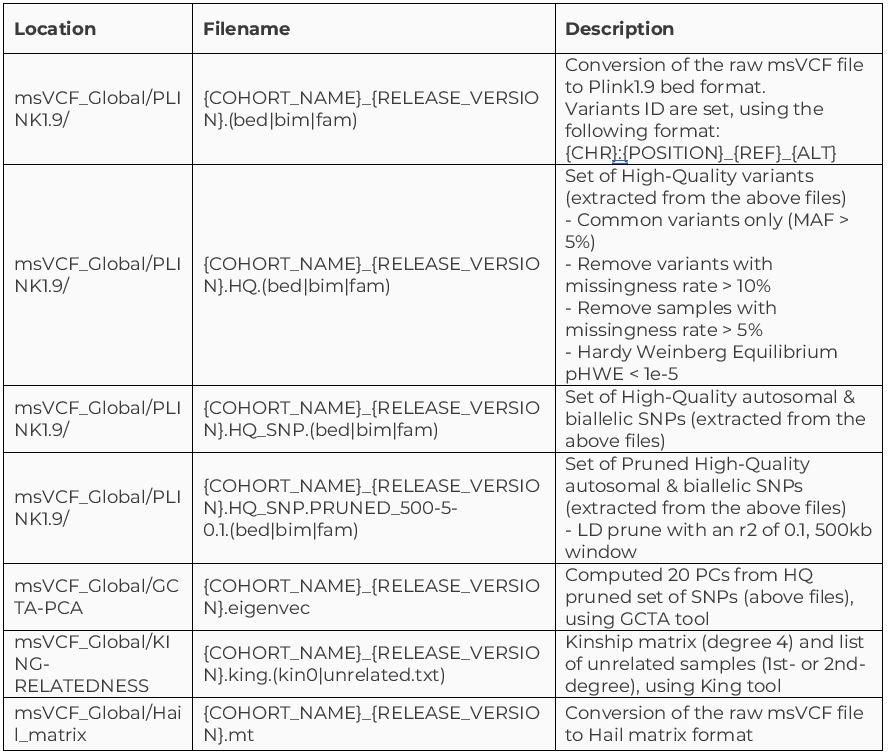
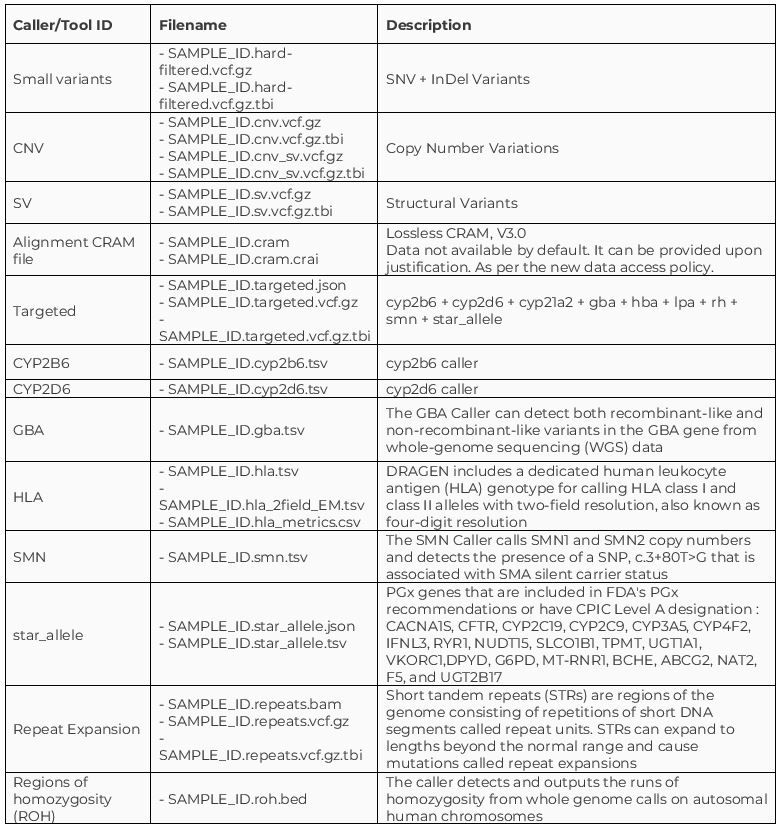
In addition to the cohort-level files produced by the Aggregation pipeline, each participant has the following genomic file types, generated by different callers:
Proteomics :
Number of participants included in the 25k genomic release and having proteomics data : 2817
Metabolomics
Number of participants included in the 25k genomic release and having metabolomics data : 2877